注意力机制
注意力起源于人类对于图片的某些特殊区域的视觉注意力和句子中的相关单词。
人们的视觉注意力使得人类可以将一些图片中的特殊区域以高分辨率查看,对于其他的部分的图片以低分辨率进行感知。
类似的,一句话或一些文本中的单词的关联性也是注意力机制的启发来源之一。比如看到”eat”就会想到”apple”。
总的来说,深度学习中的注意力机制可以广义地解释为一个重要性权重的向量:为了预测或推断一个元素,比如图像中的一个像素或句子中的一个词,我们使用注意力向量估计它与其他元素的相关性(或“关注”,如许多论文中所述),并将这些元素的值按注意力向量加权求和,作为目标的近似值。
Seq2Seq出了什么问题
Seq2Seq是一个经典的语言模型框架,粗略的看,他是通过输入一个序列输出一个新的序列。常用的应用比如机器翻译等等
他是经典的encoder-decoder架构,主要框架是:
- encoder:处理输入序列将其信息转化为文本向量或者说嵌入向量序列,长度与文本一致。这个表征可以看作序列的语义。
- decoder:用上下文向量初始化以产生变换后的输出。早期的工作仅使用编码器网络的最后状态作为解码器的初始状态。
一个例子,图中的每个单元都是基于Rnn的神经网络,可能是GRU或者LSTM
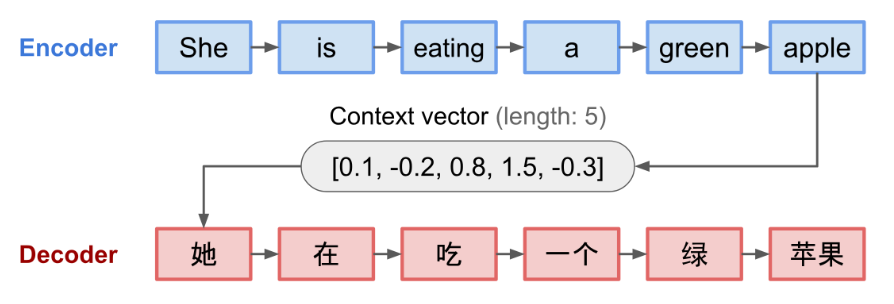
这种固定长度上下文向量设计的一个关键且明显的缺点是无法记住长句子。通常在处理完整个输入后,它已经忘记了开头部分。注意力机制(Bahdanau et al., 2015)因此诞生,以解决这个问题。(ps:那LSTM和GRU的门控可能还是会忘记?疑惑)

